17 KiB
| title | description | date | tags | |||
|---|---|---|---|---|---|---|
| Adventures in Ceph tuning | An analysis of Ceph system tuning for Hyperconverged Infrastructure | 2021-10-01 |
|
In early 2018, I started work on my Hyperconverged Infrastructure (HCI) project PVC. Very quickly, I decided to use Ceph as the storage backend, for a number of reasons, including its built-in host-level redundancy, self-managing and self-healing functionality, and general good performance. With PVC now being used in numerous production clusters, I decided to tackle optimization. This turned out to be a bit of rabbit hole, which I will detail below. Happy reading.
Ceph: A Primer
Ceph is a distributed, replicated, self-managing, self-healing object store, which exposes 3 primary interfaces: a raw object store, a block device emulator, and a POSIX filesystem. Under the hood, at least in recent releases, it makes use of a custom block storage system called Bluestore which entirely removes a filesystem and OS tuning from the equation. Millions of words have been written about Ceph, its interfaces, and Bluestore elsewhere, so I won't bore you with rehashed eulogies of its benefits here.
In the typical PVC use-case, we have 3 nodes, each running the Ceph monitor and manager, as well as 2 to 4 OSDs (Object Storage Daemons, what Ceph calls its disks and their management processes). It's a fairly basic Ceph configuration, and I use exactly one feature on top: the block device emulator, RBD (RADOS Block Device), to provide virtual machine disk images to KVM.
The main problem comes when Ceph is placed under heavy load. It is very CPU-bound, especially when writing random data, and further the replication scheme means that it is also network- and disk- bound in some cases. But primarily, the CPU speed (both in frequency and IPC) is the limiting factor.
After having one cluster placed under extreme load by a client application PostgreSQL database, I began looking into additional tuning, in order to squeeze every bit of performance I could out of the storage layer. The disks we are using are nothing special: fairly standard SATA SSDs with relatively low performance and endurance, but with upgrade costs being a concern, and the monitoring graphs showing plenty of raw disk performance on the table, I turned my attention to the Ceph layer, with very interesting results.
Ceph Tuning: A Dead End
The first thought was, of course, to tune the Ceph parameters themselves. Unfortunately for me, or, perhaps, fortunately for everyone, there isn't much to tune here. Using the Luminous release (14.x) with the Bluestore backing store, most of the defaults seem to be extremely optimal. In fact, despite finding some Red Hat blogs to the contrary, I found that almost nothing I could change would make any appreciable difference to the performance of the Ceph cluster. I had to go deeper.
The Ceph OSD Database and WAL
With Ceph Bluestore, there are 3 main components of an OSD: the main data block device, the database block device, and the write-ahead log (WAL). In the most basic configuration, all 3 are placed on the same disk. However Ceph provides the option to move the database (and WAL, if it is large enough) onto a separate block device. It isn't correct to call this a "cache", except in a general, technically-incorrect sense: the database houses mostly metadata about the objects stored on the OSD, and the WAL handles sequential write journaling and can thus be thought of similar to a RAID controller write cache, but not precisely the same. In this configuration, one can leverage a very fast device - for example, and Intel Optane SSD - to handle metadata and WAL operations for a relatively "slow" SSD block device, and thus in theory increase performance.
Turbo-charging My Cluster with Intel Optane SSDs
I decided to test this out myself first by purchasing a set of 3 Intel Optane DC P4801X 100GB M.2-form-factor SSDs. I was able to obtain these drives, brand new, for the bargain-basement price of $80 CAD each, less than 1/4 of their MSRP on release in 2019. I guess there isn't much market for these very small but very fast drives out there. I used a set of PCIe HHHL to M.2 adapter cards to install the SSDs into my servers, and I was quickly able to validate their near-unfathomable performance. At anything less than a 256-depth queue with 8 workers, doing 4k random read and write tests, I was more limited by the CPU usage of the fio process than I was by the SSDs, and during these tests I was even able to exceed the official rated specifications - in both IOPS and raw bandwidth, but not latency - by as much as 10%.
Emboldened by the sheer performance of the drives, I quickly implemented OSD DB offloading in PVC, added the Optane SSDs to my existing pair-per-node of Intel DC S3700 800GB SSD OSDs, and began benchmarking.
The Bane of Hyperconverged Architectures: Sharing Resources
I quickly noticed a slight problem, however. My home cluster, which was doing these tests, is a bit of a hodge-podge of server equipment, and runs a fair number (68 at the time of testing) of virtual machines across its 3 nodes. The hardware breakdown is as follows:
| Part | node1 | node2 + node3 |
|---|---|---|
| Chassis | HP Proliant DL-360 G6 | Dell R430 |
| CPU | 2x Intel E5-5649 | 1x Intel E5-2620 v4 |
| Memory | 144 GB DDR3 (18x 8 GB) | 128 GB DDR4 (4x 32 GB) |
The VMs themselves also range from basically-idle to very CPU-intensive, with a wide range of vCPU allocations. I quickly realized that there might be another tuning aspect to consider: CPU (and NUMA, for node1) pinning.
I decided to try implementing a basic CPU pinning scheme with the cpuset Linux utility. This tool allows the administrator to create static csets, which are logical groups assigned to specific CPUs, and then place processes - either during runtime or at process start - into these csets. So, in addition to testing the Optane drives, I decided to also test Optane-less configurations whereby specific numbers of cores (and their corresponding hyperthreads) were dedicated to the Ceph OSDs instead of all CPUs shared by both OSDs, VMs, and PVC host daemons.
Ultimately, the disparate configurations here do present potential problems in interpreting the results, however within this particular cluster the comparisons are valid, and I do hope to repeat these tests (and update this post) in the future when I'm able to simplify and unify the server configurations.
Test Explanation
The benchmarks themselves were run with the system in production, running the full set of VMs. This was done, both for practical reasons, but also to simulate a real-world scenario with numerous noisy neighbours. While this might affect a single random test, I ran 3 tests each and staggered them over time to minimize the impact of bursty VM effects. Further the cpuset tuning would be fairly moot without additional real load on the nodes, and thus I believe this to be a worthwhile assumption. A future addition to the results might be to run a similar set of tests against an empty cluster, and if and when I am able to do so, I will add to this post.
The tests were run with PVC's in-built benchmark system, which creates a new, dedicated Ceph RBD volume and then runs the fio tests against it directly using the rbd engine. To ensure fio itself was not limited by noisy neighbours, the node running the tests was flushed of VMs.
For the 3 cpuset tests, the relevant cset configuration was applied to all 3 nodes, regardless of the number of or load in the VMs, and putting the fio process inside the "VM" cpuset. Thus the CPUs set aside for them were completely dedicated to the OSDs.
The Benchmark Results in 6 Graphs
The results were fairly interesting, to say the least. First, I'll present the 6 key indicator graphs I obtained from the benchmark data, and then run through what they mean. Within each graph, the 5 tests are as follows:
- No-O, No-C: No Optane DB/WAL drive, no
cpusettuning. - O, No-C: Optane DB/WAL drive, no
cpusettuning. - No-O, C=2: No Optane,
cpusetOSD group with 2 CPU cores (+ hyperthreads, onnode1within CPU0 NUMA domain) - No-O, C=4: No Optane,
cpusetOSD group with 4 CPU cores (+ hyperthreads, onnode1within CPU0 NUMA domain) - No-O, C=6: No Optane,
cpusetOSD group with 6 CPU cores (+ hyperthreads, onnode1within CPU0 NUMA domain)
It's worth noting that the 5th test left just 2 CPU cores (+ hyperthreads) to run VMs on hv2 - the performance inside them was definitely sub-optimal!
Each test, in each configuration mode, was run 3 times, with the results presented here being an average of the results of the 3 tests.
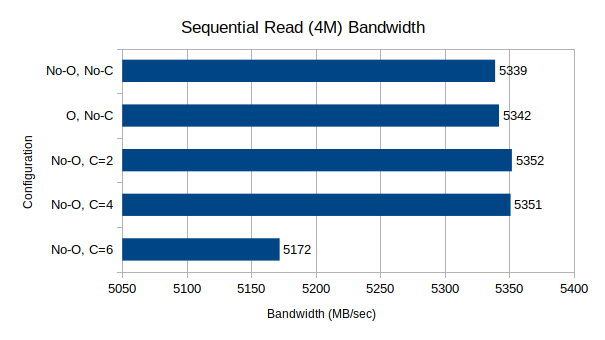
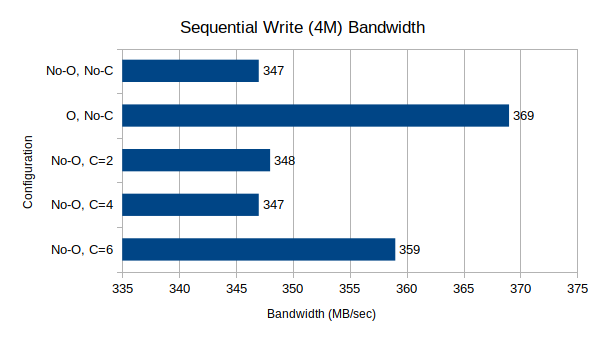
Test Suite 1: Sequential Read/Write Bandwidth, 4M block size, 64-depth queue
These two tests measure raw sequential throughput at a very large block size and relatively high queue depth.
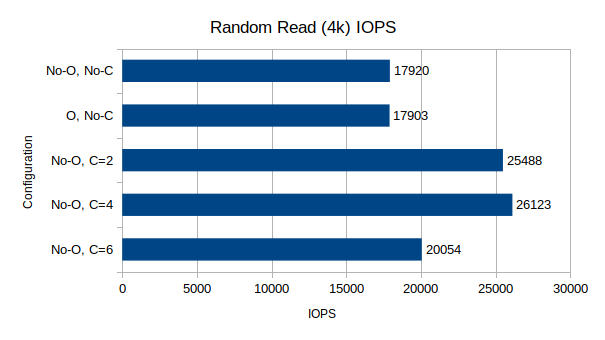
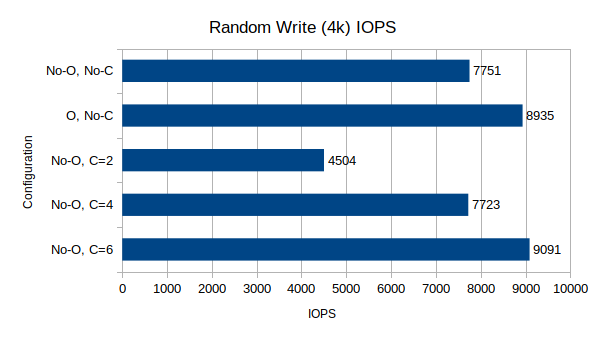
Test Suite 2: Random Read/Write IOPS, 4k block size, 64-depth queue
These two tests measure IOPS performance at a very small block size and relatively high queue depth.
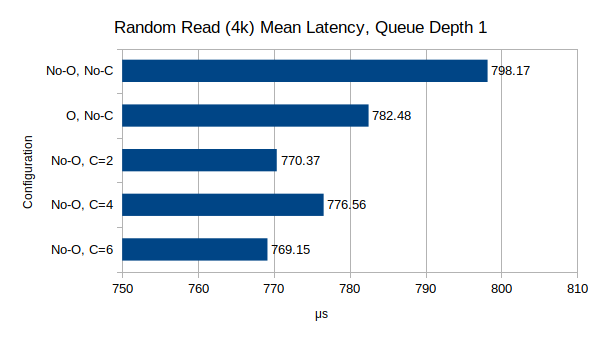
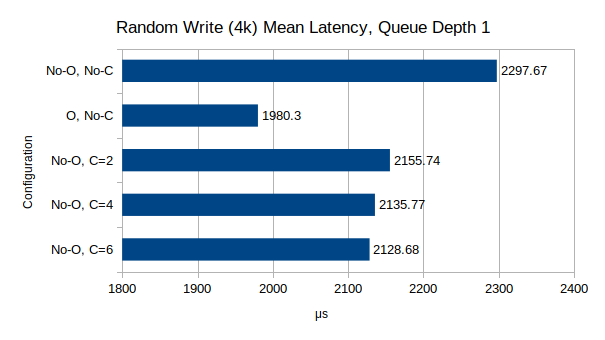
Test Suite 3: Random Read/Write Latency, 4k block size, 1-depth queue
These two tests measure average request latency at a very small block size and single queue depth.
Benchmark Analysis
Sequential Performance
For reads, the performance is nearly identical, and almost within margin-of-error, for the first 3 data points. The Optane drive did not seem to make any difference to sequential read performance, which would be expected since the roughly 1GB of metadata per OSD can easily be cached in the OSD's 4GB of allowed RAM. However when using 6 CPU cores (theoretically, 3 per OSD), the read performance drops by a fairly significant margin. I don't have any explanation for this drop.
For writes, the performance shows some very noteworthy results. The Optane drive makes a noticeable, thought not significant, difference in the write performance, likely due to the WAL. A larger drive, and thus larger WAL, might make an even more significant improvement. The cpuset tuning, for 2 and 4 CPU csets`, seems to make no difference over no limiting; however once the limit was raised to 6 CPU cores, write performance did increase somewhat, though not as noticeably as with the Optane cache.
The two main takeaways from these tests seem to be that (a) Optane database/WAL drives do have a noticeable effect on write performance; and (b) that dedicating 3 (or potentially more) CPU cores per OSD increases write performance while decreasing read performance. The increase in write performance would seem to indicate a CPU bottleneck is occurring with the lower CPU counts (or when contending with VM/fio processes), but this does not match the results of the read tests, which in the same situation should increase as well. One possible explanation might lie in the Ceph monitor processes, which direct clients to data objects on OSDs and were in the "VM" cset, but in no test did I see the ceph-mon process become a significant CPU user. Perhaps more research into the inner workings of Ceph OSDs and CRUSH maps will reveal the source of this apparent contradiction, but at this time I can not explain it.
Random I/O Performance
Random I/O performance seems to show very similar things to sequential I/O performance, though with its own interesting caveats.
For reads, it continues to be clear that the Optane drive does not make any noticeable difference to the performance. The cpuset results however are far more interesting. When limiting to 2 or 4 CPUs, the random read performance increases by over 40%, however like the write test, limiting to 6 CPUs results in a marked drop, though still higher than the baseline.
For writes, the story is even more interesting. Random writes are, by far, in my experience, the most CPU-demanding Ceph I/O operation, and the results demonstrate this. Like sequential writes, the Optane drive produces a noticeable, though again not dramatic, increase in write IOPS. The more interesting story comes with the cpuset tuning. Limiting the OSDs to just 2 CPUs, the write IOPS are nearly halved compared to the baseline. Increasing this to 4 CPUs returns the write performance to the baseline, while increasing it again to 6 increases the performance yet again, surpassing the non-cset Optane performance, thought the increase from 4 to 6 is not as dramatic as from 2 to 4, which definitely points towards a plateau at 8 or 10 cores for 2 OSDs.
One interesting takeaway from this result is the breaking of my assumption that Ceph OSDs were primarily single-threaded applications limited by raw single-core performance. They are clearly not, and one OSD will consume resources from many CPU cores. When building a HCI cluster, this becomes a much more important consideration, making very high-core-count CPUs, even slightly slower ones, a more attractive option. More testing to evaluate the differences that speed and IPC can make across multiple CPU frequencies and generations would be very useful in further narrowing down the optimal performance range, though this is currently outside of my personal capabilities.
Random I/O Latency
The final test concerns latency, using a single depth queue to measure latency almost exclusively. And unlike the other two results, these results do line up with my intuitive expectations.
For reads, the Optane drive does drop the latency slightly, likely due to the lower latency of metadata reads from the DB volume. Though the result is pronounced in the graph due to the scale, it really only amounts to a 2% performance difference. The cpuset results show a further latency drop, of roughly another 2-3%, which does seem to indicate that CPU contention can make a big difference in the latency of read operations, though not as dramatically as raw performance.
For writes, the Optane drive is a clear winner, reducing the average latency by almost 15%. This combined with the cpuset results showing a steady, if minimal, reduction in latency as more CPU cores are dedicated the OSDs, definitely points towards the CPU-sensitive nature of Ceph latency, since clearly the software component accounts for over 130x the latency that the drive does (~15 microseconds for a direct write versus 1980 microseconds for a Ceph write).
Overall Conclusions and Takeaways
Going into this project, I had hoped that both the Optane drive and the cpuset core dedication would make profound, dramatic, and consistent differences to the Ceph performance. However, the results instead show, like much in the realm of computer storage, trade-offs and caveats. As takeaways from the project, I have the following 4 main thoughts:
-
For write-heavy workloads, especially random writes, an Optane DB/WAL device can make a not-insignificant difference in overall performance. However, the money spent on an Optane drive might better be spent elsewhere...
-
CPU is, as always with Ceph, king. The more CPU cores you can get in your machine, and the faster those CPU cores are, the better, even ignoring the VM side of the equation. Going forward I will definitely be allocating more than my original 1 CPU core per OSD assumption into my overall CPU core count calculations, with 4 cores per OSD being a good baseline.
-
While I have not been able to definitely test and validate it myself, it seems that
cpusetoptions are, at best, only worthwhile in very read-heavy use-cases and in cases where VMs are extremely noisy neighbours and there are insufficient physical CPU cores to satiate them. While there is a marked increase in random I/O performance, the baseline write performance matching the 4-core limit seems to show that the effect would be minimized the more cores there are for both workloads to use, and the seemingly-dramatic read improvement might be due to the age of some of the CPUs in my particular cluster. More investigation is definitely warranted. -
While it was not exactly tested here, memory performance would certainly make a difference to read performance. Like with CPUs, I expect that read rates would be much higher if all nodes were using the latest DDR4 memory.
Hopefully this analysis of my recent Ceph tuning adventures was worthwhile, and that you learned something. And of course, I definitely welcome any comments, suggestions, or corrections!